Created at : 2024-05-13 11:55
Auther: Soo.Y
Ver 02 연구 결과물
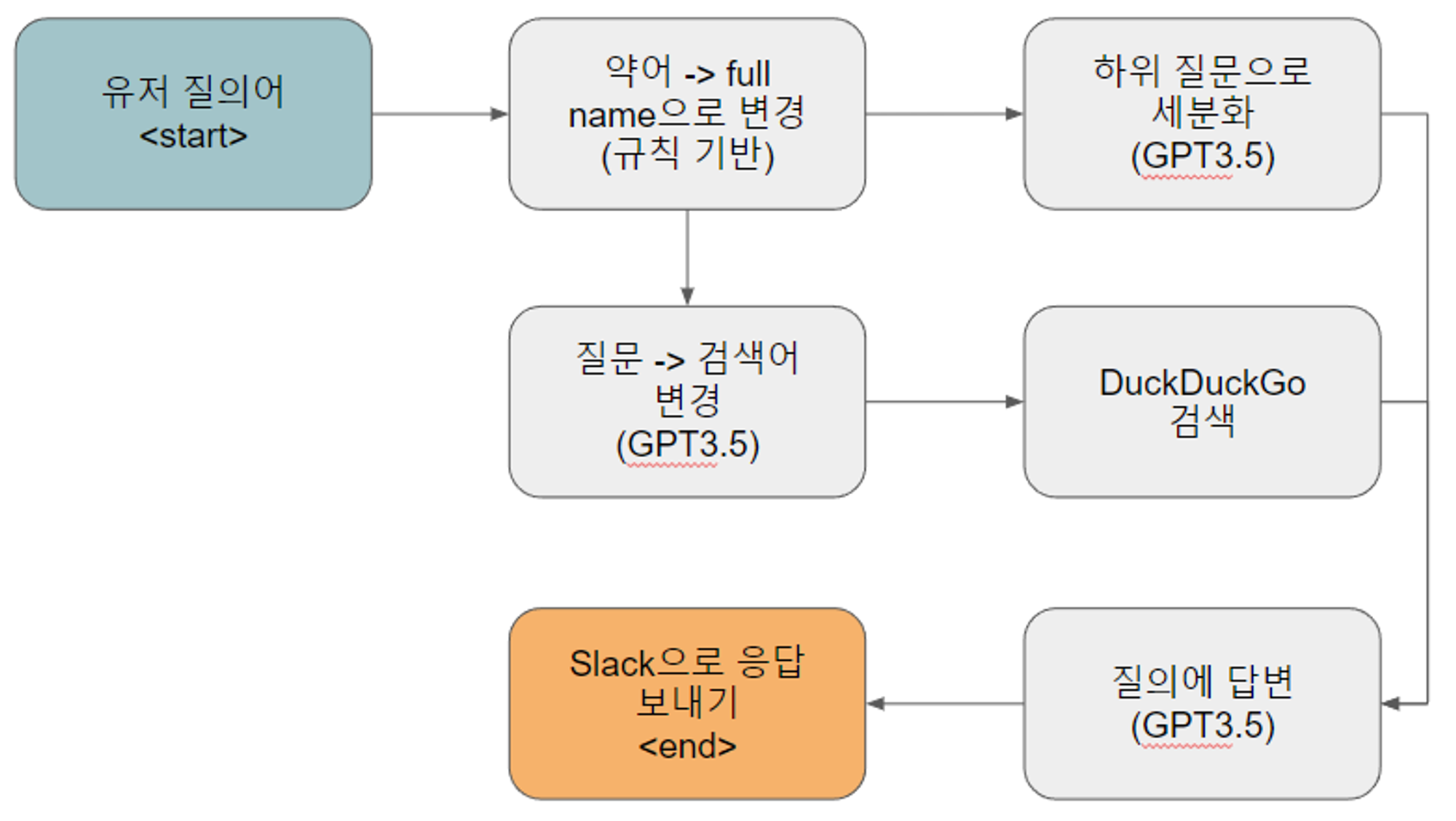
Ver 02에 대한 전체 프로세스는 아래 그림과 같이 구성되었습니다.
- 보안 prompt를 Ver 01에서 제거함
- 보안 prompt가 없더라도 prompt가 유출되는 현상이 있는지 확인하고자 함
- 약어를 풀네임으로 변경하여 LLM 모델이 약어에 대한 의미를 정확하게 알 수 있도록 구성함
- DuckDuckGo의 검색을 항시로 변경함
- DuckDuckGo에서 검색되는 작은 정보를 유입해서 LLM 모델이 학습하지 않은 정보에 대해서 도움을 주지 위함
- DuckDuckGo의 context가 많은 정보를 내포하지 않기 때문에 DuckDuckGo를 판별하는 프로세스는 제거함
Cast study
- GPT4.0(ref) : 기존 프롬프트 + 규칙 기반을 적용하여 질문에 답변
- GPT3.5(ours) : 개선된 프로세스를 적용하여 질문에 답변
1. 질문 : ReLU에 대해서 알려줘.
답변 결과
GPT4.0(ref)
ReLU(Rectified Linear Unit)는 인공 신경망에서 사용되는 활성화 함수 중 하나입니다. 이 함수는 입력이 0보다 클 때는 입력을 그대로 출력하고, 0 이하일 때는 0을 출력합니다. 수학적으로는 ReLU 함수는 f(x) = max(0, x)로 표현됩니다.
ReLU 함수는 다음과 같은 특징을 가지고 있습니다:
- 비선형성: ReLU는 비선형 함수이기 때문에 신경망이 선형 문제뿐만 아니라 비선형 문제도 해결할 수 있게 해줍니다.
- 계산 효율성: ReLU의 계산이 매우 간단하기 때문에, 다른 활성화 함수에 비해 계산 비용이 낮습니다. 이는 신경망의 학습 속도를 높여줍니다.
- 그래디언트 소실 문제 완화: 심층 신경망에서는 그래디언트가 네트워크를 거슬러 올라갈 때 점점 작아지는 경향이 있는데, ReLU를 사용하면 이 문제를 어느 정도 완화할 수 있습니다. 그러나 ReLU는 0 이하의 값에서 그래디언트가 0이 되므로, 일부 뉴런이 ‘죽는’ 문제가 발생할 수 있습니다.
ReLU의 변형으로는 Leaky ReLU, Parametric ReLU(PReLU), Exponential Linear Unit(ELU) 등이 있으며, 이들은 ReLU의 단점을 보완하기 위해 제안되었습니다.
ReLU는 주로 은닉층에서 활성화 함수로 사용되며, 다양한 딥러닝 모델에서 널리 사용되고 있습니다.
GPT3.5(ours)
- ReLU는 Rectified Linear Unit의 약자로, 활성화 함수 중 하나입니다.
- ReLU는 입력값이 0보다 작을 때는 0으로, 0보다 큰 값에 대해서는 그 값을 그대로 출력하는 함수입니다.
- ReLU는 기존의 활성화 함수들보다 학습 속도가 빠르고, 구현이 간단하여 널리 사용됩니다.
- ReLU의 장점은 학습 속도가 빠르고, 구현이 간단하며, vanishing gradient 문제를 해결할 수 있습니다. 단점은 입력값이 음수일 때는 0으로 처리되어 dying ReLU 문제가 발생할 수 있습니다.
- ReLU는 Sigmoid나 Tanh와 비교했을 때, vanishing gradient 문제를 해결하고 학습 속도가 빠르지만, dying ReLU 문제가 발생할 수 있습니다. Leaky ReLU는 dying ReLU 문제를 해결하기 위해 나온 함수로, 입력값이 음수일 때 작은 기울기를 갖는다는 차이가 있습니다.
Opus(ref)
안녕하세요! ReLU에 대해 설명 드리겠습니다.
ReLU는 Rectified Linear Unit의 약자로, 인공신경망(Artificial Neural Network)에서 활성화 함수(Activation Function)로 자주 사용됩니다. ReLU 함수는 입력값이 0보다 작으면 0을, 0보다 크거나 같으면 입력값 그대로를 출력합니다. 수식으로 표현하면 다음과 같습니다:
ReLU(x) = max(0, x)
ReLU 함수의 장점은 다음과 같습니다:
- 계산이 간단하고 효율적입니다. 입력값이 양수인 경우 그대로 출력하므로 계산량이 적습니다.
- 기울기 소실(Vanishing Gradient) 문제를 완화시킵니다. ReLU는 양수 입력에 대해 기울기가 1이므로, 역전파(Backpropagation) 과정에서 기울기가 사라지는 문제를 완화할 수 있습니다.
- 희소성(Sparsity)을 유도합니다. ReLU는 음수 입력에 대해 0을 출력하므로, 신경망의 일부 뉴런이 비활성화되어 희소한 표현을 학습할 수 있습니다.
Python에서 ReLU 함수를 구현하면 다음과 같습니다:
`import numpy as np
def relu(x): return np.maximum(0, x)`
ReLU는 심층 신경망(Deep Neural Network)에서 널리 사용되며, 이미지 분류, 객체 탐지, 자연어 처리 등 다양한 분야에서 좋은 성능을 보여줍니다. 하지만 ReLU의 변형인 Leaky ReLU, PReLU 등도 존재하며, 상황에 따라 더 적합한 활성화 함수를 선택할 수 있습니다.
Haiku(ours)
안녕하세요, 저는 AI 전문가 김용담입니다. 학생 여러분의 질문에 성실히 답변드리겠습니다.
- ReLU (Rectified Linear Unit)란 무엇인가요? ReLU는 딥러닝 모델에서 널리 사용되는 비선형 활성화 함수입니다. 이 함수는 입력값이 0보다 작으면 0을 출력하고, 0보다 크면 입력값 그대로를 출력합니다. 즉, 입력값이 양수이면 그대로 통과시키고, 음수이면 0으로 만들어버리는 것이죠.
- ReLU는 신경망에서 어떻게 작동하나요? ReLU는 신경망의 은닉층에서 사용됩니다. 입력값이 양수이면 그대로 통과시켜 다음 층으로 전달하고, 음수이면 0으로 만들어버립니다. 이를 통해 신경망에 비선형성을 부여하고, 기울기 소실 문제를 해결할 수 있습니다.
- ReLU의 장점은 무엇인가요? ReLU의 가장 큰 장점은 기울기 소실 문제를 해결할 수 있다는 것입니다. 기울기 소실 문제는 신경망 학습 시 기울기가 점점 작아져 학습이 어려워지는 문제인데, ReLU는 이를 효과적으로 해결할 수 있습니다. 또한 ReLU는 학습 속도가 빠르고, 희소성이 높아 메모리 사용량도 적습니다.
- ReLU의 단점은 무엇인가요? ReLU의 단점은 입력값이 음수일 때 0으로 만들어버리기 때문에, 음수 값에 대한 정보를 완전히 잃어버린다는 것입니다. 이를 해결하기 위해 Leaky ReLU, ELU 등의 변형된 활성화 함수가 제안되었습니다.
- ReLU를 개선하거나 변형할 수 있는 방법은 무엇인가요? ReLU의 단점을 보완하기 위해 다양한 변형된 활성화 함수가 제안되었습니다. Leaky ReLU는 음수 값에 대해서도 일정 비율로 출력을 내보내고, ELU는 음수 값에 대해 지수 함수를 사용하여 출력을 내보냅니다. 이러한 변형된 활성화 함수들은 ReLU의 장점을 유지하면서도 단점을 보완할 수 있습니다.
Cost 결과
GPT4.0(ref)
- Total tokens: 786
- Input tokens: 289
- Output tokens: 497
- LLM Requests: 1
- Total Cost (USD): $0.0178
- Total Cost (KRW): 24 원
GPT3.5(ours)
- Total tokens: 1308
- Input tokens: 904
- Output tokens: 404
- LLM Requests: 3
- Total Cost (USD): $0.0010580000000000001
- Total Cost (KRW): 1 원
Opus(ref)
- Total tokens: 942
- Input tokens: 314
- Output tokens: 628
- LLM Requests: 1
- Total Cost (USD): $0.05181
- Total Cost (KRW): 70 원
Haiku(ours)
- Total tokens: 1702
- Input tokens: 763
- Output tokens: 939
- LLM Requests: 3
- Total Cost (USD): $0.0013644999999999998
- Total Cost (KRW): 2 원
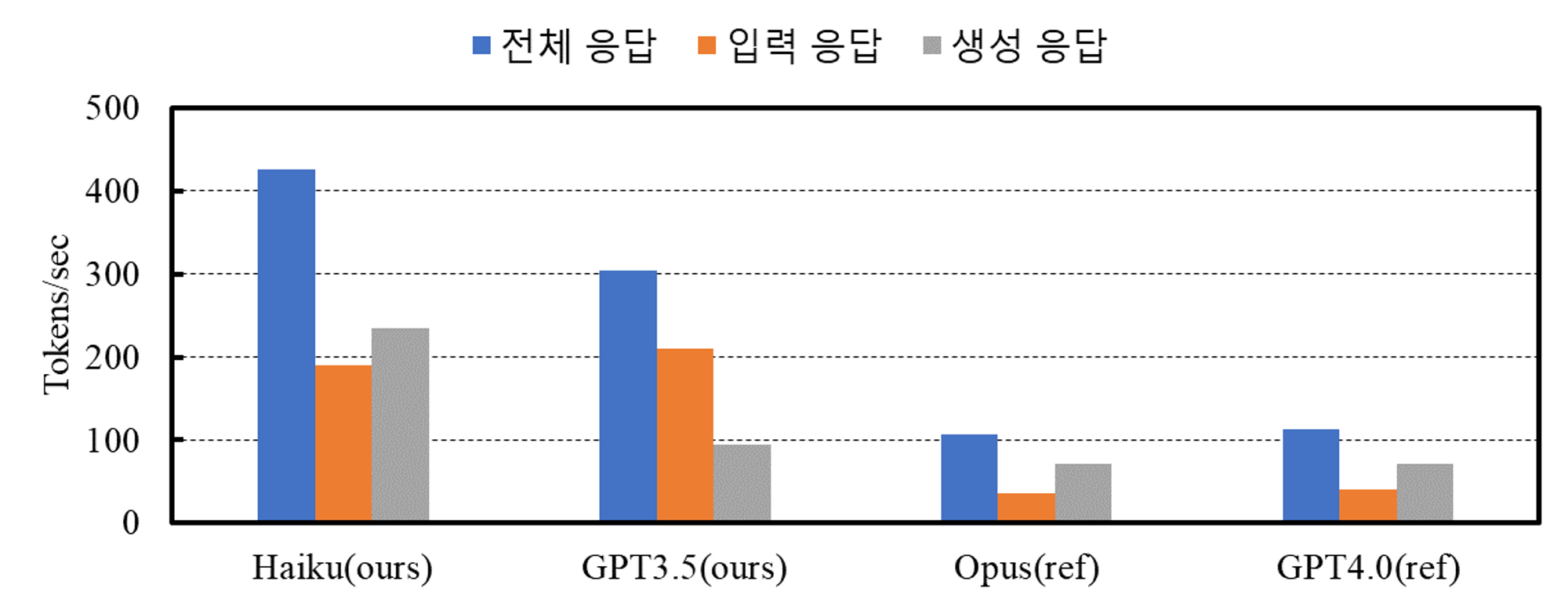
응답 시간
GPT4.0(ref) : 14.5
Opus(ref) : 24.1
GPT3.5(ours) : 12.1
Haiku(ours) : 10
결론
- Sub-questions 기법으로 인해 Ver01에 비해 풍부한 답변을 생성함
- 질문에 대한 세부적인 하위 질문으로 인해 답변의 양이 풍부해짐
- 하위 질문으로 인해 간단한 질문에도 상세한 답변이 가능함
- Ver01에 비해 축소된 절차로 인해 요금이 상대적으로 감소함
- GPT3.5 기준 : 24배(GPT), 70배(Opus)
- Haiku 기준 : 12배(GPT), 35배(Opus)
- 응답 시간(생성 토큰 기준)은 Opus(ref)가 오래 걸렸고 Haiku(ours)가 가장 빨랐음
- 답변의 품질은 ReLU의 기본적인 정보는 모든 모델이 보유하고 있어서 할루시네이션은 없다고 판단됨
- 단, ReLU 질문에 대해서 코드 설명이 없다. (feat. 코드를 보여 달려고 하면 기존보다 잘 생성해주지는 않는다.)
2. 질문 : DoRA에 대해서 알려줘.
답변 결과
GPT4.0(ref)
DoRA(Weight-Decomposed Low-Rank Adaptation)는 인공지능 분야에서 모델의 가중치를 분해하여 저차원으로 변환하는 기법 중 하나입니다. 이 방법은 특히 모델의 파라미터 수를 줄이면서도 성능을 유지하거나 향상시키고자 할 때 유용합니다. DoRA는 기본적으로 모델의 가중치를 저차원 공간으로 효율적으로 매핑하고, 이를 통해 모델의 복잡성을 줄이면서도 중요한 정보를 보존하려는 목적을 가지고 있습니다.
이 기법은 크게 두 부분으로 나눌 수 있습니다. 첫 번째는 가중치를 저차원으로 분해하는 과정이고, 두 번째는 분해된 가중치를 사용하여 모델을 학습시키는 과정입니다. 가중치 분해는 일반적으로 특이값 분해(Singular Value Decomposition, SVD)와 같은 수학적 방법을 사용하여 수행됩니다. 이렇게 분해된 가중치는 원래의 고차원 가중치에 비해 훨씬 적은 수의 파라미터를 가지게 되며, 이를 통해 모델의 학습 및 추론 속도를 향상시킬 수 있습니다.
DoRA를 사용하는 주된 이점 중 하나는 모델의 과적합(overfitting)을 줄일 수 있다는 점입니다. 가중치를 저차원으로 분해함으로써 모델이 학습 데이터에 지나치게 최적화되는 것을 방지하고, 일반화 능력을 향상시킬 수 있습니다. 또한, 메모리 사용량을 줄이고, 모델의 추론 속도를 빠르게 할 수 있어, 특히 모바일이나 임베디드 시스템과 같이 자원이 제한된 환경에서 유용합니다.
DoRA는 다양한 인공지능 모델, 특히 심층 신경망(Deep Neural Networks)에 적용될 수 있으며, 이미지 처리, 자연어 처리, 음성 인식 등 다양한 분야에서 활용될 수 있습니다. 이 기법을 통해 모델의 성능을 유지하면서도 효율성을 크게 향상시킬 수 있어, 인공지능 분야에서 중요한 연구 주제 중 하나로 자리잡고 있습니다.
GPT3.5(ours)
- Weight-Decomposed Low-Rank Adaptation (DoRA)은 사전 훈련된 가중치를 두 부분, 크기와 방향으로 분해하여 사용하는 새로운 기술입니다. 이를 통해 LoRA와 같은 기존 기술보다 더 효율적으로 모델을 조정할 수 있습니다.
- Weight-Decomposed Low-Rank Adaptation (DoRA)는 AI 분야에서 어떻게 작동하나요? DoRA는 사전 훈련된 모델의 가중치를 크기와 방향으로 분해하여 작은 일부분만을 조정함으로써 모델을 더 잘 맞출 수 있습니다. 이를 통해 모델의 학습 능력과 안정성을 향상시키면서 추가적인 추론 비용을 피할 수 있습니다.
- Weight-Decomposed Low-Rank Adaptation (DoRA)를 사용하는 것의 장점은 무엇인가요? DoRA를 사용하면 모델을 더 효율적으로 조정할 수 있으며, 학습 능력과 안정성을 향상시킬 수 있습니다. 또한 추가적인 추론 비용을 피할 수 있어 더 효율적인 모델을 만들 수 있습니다.
- Weight-Decomposed Low-Rank Adaptation (DoRA)가 일반적으로 사용되는 특정 응용 분야나 사용 사례가 있나요? DoRA는 주로 작은 데이터셋에 대해 모델을 조정할 때 사용됩니다. 예를 들어, 특정 작업에 대해 사전 훈련된 모델을 더 잘 맞출 때 DoRA를 사용할 수 있습니다.
- AI 시스템에서 Weight-Decomposed Low-Rank Adaptation (DoRA)의 구현 과정을 설명해 줄 수 있나요? DoRA를 구현하기 위해서는 먼저 사전 훈련된 모델의 가중치를 크기와 방향으로 분해해야 합니다. 그런 다음 작은 일부분의 가중치만을 조정하여 모델을 새로운 데이터셋에 더 잘 맞출 수 있습니다. PyTorch와 같은 프레임워크를 사용하여 DoRA를 구현할 수 있습니다.
Opus(ref)
안녕하세요! DoRA(Weight-Decomposed Low-Rank Adaptation)에 대해 설명해드리겠습니다.
DoRA는 사전학습된(pre-trained) 언어 모델을 다운스트림 태스크(downstream task)에 적응시키는 파라미터 효율적인 fine-tuning 방법입니다. 주로 BERT나 RoBERTa 같은 대규모 언어 모델을 특정 태스크에 맞게 미세조정(fine-tuning)할 때 사용됩니다.
DoRA의 핵심 아이디어는 사전학습 모델 파라미터 행렬을 여러 개의 낮은 랭크(low-rank) 행렬로 분해하는 것입니다. 이렇게 하면 fine-tuning 시 학습해야 할 파라미터 수를 크게 줄일 수 있어 계산 및 메모리 효율성이 높아집니다.
구체적으로, DoRA는 다음과 같은 과정을 거칩니다:
- 사전학습 모델 파라미터 행렬 W를 여러 개의 낮은 랭크 행렬 U와 V로 분해합니다. 즉, W ≈ UV로 근사합니다.
- Fine-tuning 시에는 U와 V 행렬만 학습하고, W는 고정시킵니다. 이렇게 하면 학습 파라미터 수가 |W|에서 |U| + |V|로 크게 감소합니다.
- 추론(inference) 시에는 U와 V를 곱해 W를 근사한 후, 이를 이용해 예측합니다.
이처럼 DoRA를 활용하면 대규모 언어 모델을 효율적으로 fine-tuning하여 다양한 태스크에 적용할 수 있습니다. 특히 파라미터 수를 줄여 계산량과 메모리 사용량을 절감할 수 있다는 장점이 있습니다.
DoRA에 대해 추가로 궁금한 점이 있다면 말씀해 주세요. 더 자세히 설명해 드리겠습니다!
Haiku(ours)
안녕하세요, 김용담 교수입니다. 오늘 DoRA(Weight-Decomposed Low-Rank Adaptation)에 대해 자세히 설명드리겠습니다.
- DoRA의 목적: DoRA는 기존의 Fine-Tuning(FT) 기법과 Low-Rank Adaptation(LoRA) 기법의 장점을 결합하여, 모델의 학습 능력을 향상시키는 것이 목적입니다. FT는 모델 전체를 미세 조정하여 성능을 높일 수 있지만, 많은 계산 자원이 필요합니다. 반면 LoRA는 모델의 일부만 조정하여 효율적이지만, 성능이 FT만큼 좋지 않습니다. DoRA는 이 두 가지 방법의 장점을 결합하여 성능과 효율성을 모두 높이고자 합니다.
- DoRA의 핵심 구성 요소: DoRA는 모델의 가중치를 크기(magnitude)와 방향(direction)의 두 가지 요소로 분해합니다. 그리고 LoRA 기법을 사용하여 방향 요소만 조정합니다. 이를 통해 모델의 핵심 특성은 유지하면서도 특정 작업에 맞게 효율적으로 조정할 수 있습니다.
- DoRA와 다른 저랭크 적응 기법의 차이점: DoRA는 기존의 LoRA와 달리, 가중치를 크기와 방향으로 분해하여 조정합니다. 이를 통해 모델의 핵심 특성을 유지하면서도 특정 작업에 맞게 효율적으로 조정할 수 있습니다. 또한 DoRA는 FT와 유사한 학습 능력을 보여주는 것으로 알려져 있습니다.
- DoRA의 장단점: 장점:
- FT와 유사한 학습 능력을 보여줌
- 모델의 핵심 특성을 유지하면서도 효율적으로 조정 가능
- 계산 자원이 적게 필요
단점:
- 가중치 분해 과정이 복잡할 수 있음
- 특정 모델 아키텍처에만 적용 가능할 수 있음
- DoRA의 적용 범위: DoRA는 주로 언어 모델(LLM)이나 비전 트랜스포머 등의 신경망 모델에 적용될 수 있습니다. 하지만 모델의 아키텍처에 따라 적용 방식이 달라질 수 있습니다. 따라서 DoRA를 다른 모델에 적용할 때는 모델의 특성을 잘 이해하고 적절히 조정해야 합니다.
이상으로 DoRA에 대한 설명을 마치겠습니다. 궁금한 점이 더 있으시면 언제든 질문해 주시기 바랍니다.
Cost 결과
GPT4.0(ref)
- Total tokens: 1036
- Input tokens: 300
- Output tokens: 736
- LLM Requests: 1
- Total Cost (USD): $0.025079999999999998
- Total Cost (KRW): 34 원
GPT3.5(ours)
- Total tokens: 1747
- Input tokens: 965
- Output tokens: 782
- LLM Requests: 3
- Total Cost (USD): $0.0016554999999999999
- Total Cost (KRW): 2 원
Opus(ref)
- Total tokens: 1014
- Input tokens: 326
- Output tokens: 688
- LLM Requests: 1
- Total Cost (USD): $0.05649
- Total Cost (KRW): 77 원
Haiku(ours)
- Total tokens: 2099
- Input tokens: 1049
- Output tokens: 1050
- LLM Requests: 3
- Total Cost (USD): $0.0015747499999999998
- Total Cost (KRW): 2 원
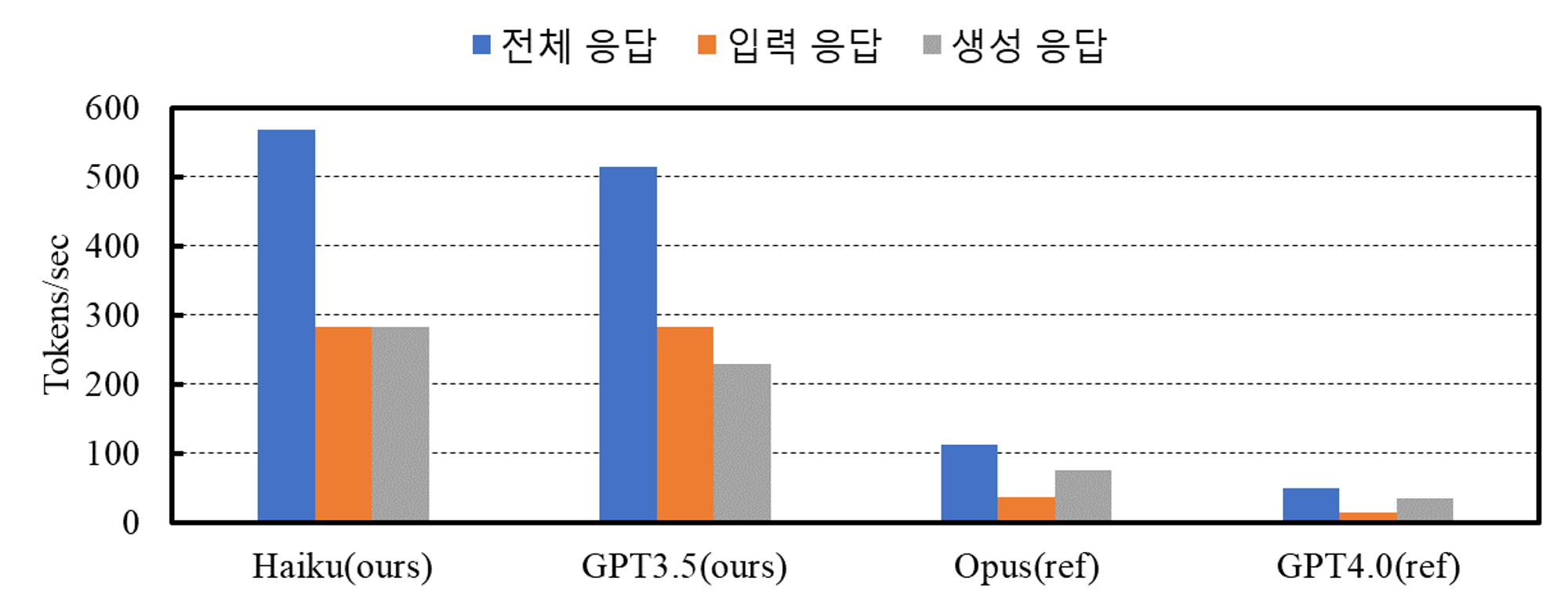
응답 시간
GPT4.0(ref) : 20.8
Opus(ref) : 28.4
GPT3.5(ours) : 18.1
Haiku(ours) : 11.1
결론
- 질문이 LLM 모델의 학습 기간을 벗어난 경우에는 잘못된 정보를 도출하는 경우가 발생함
- 약어를 풀네임으로 변경했음에도 불구하고 두루뭉술한 정보를 보여주고 있음
- 이런 부분에 대해서는 RAG를 통해서 보충 정보가 요구됨
- 단, Haiku(ours)에서 sub-questions를 도입하니 알맞은 정보를 생성함
- Ver01에 비해 17배~37배 정도 비용 감소됨
- 응답 시간은 Opus(ref)가 가장 오래 걸렸으며, Haiku(ours)가 11.1s로 가장 빨랐음
- Haiku가 응답시간도 빠르고 다른 LLM 모델에 비해서 가장 품질 좋은 답변을 생성함
- Ver02의 단점은 간단한 인사말(안녕)에 대해서 진지하게 질문을 했다고 생각하여 안녕에 대한 정의 등을 설명하게 됨
- sub-questions의 단점과 sub-questions에 대한 답변에 의해 발생되었다고 판단됨
- 단, Q&A의 특성상 인사말과 같은 질문에 대해서는 잘못된 답변이 생성되더라도 유저가 원하는 지문에 대해서 상세한 내용을 제공하는 점은 장점이다고 생각됨
관련 문서
Gradio 데모 버전 https://github.com/coding-is-coffee/yongdambot/blob/test_develop/examples/gradio_Low_LLM_Ver02.ipynb