Created at : 2024-06-26 11:48
Auther: Soo.Y
목차
- 신경망이란?
- 신경망의 역사
- 신경망의 기본 구성 요소
- 신경망의 동작 원리
- 신경망의 학습 과정
- 다양한 신경망의 유형
- 신경망의 주요 응용 분야
- 신경망 구현 예제
- 신경망의 장단점
- 결론
1. 신경망이란?
신경망(Neural Network)은 인간 뇌의 신경세포 구조를 본떠 만든 인공 지능 모델입니다. 여러 개의 인공 뉴런이 계층적으로 연결되어 있으며, 복잡한 패턴 인식과 데이터 분석을 수행하는 데 사용됩니다.
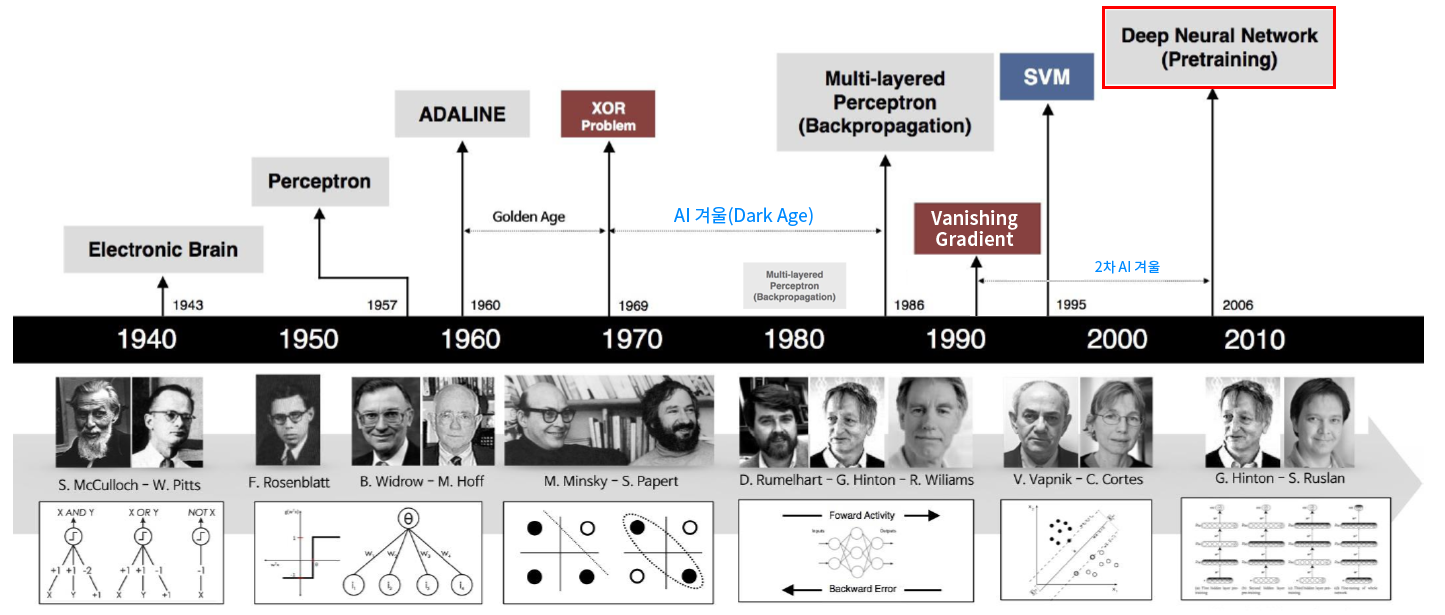
2. 신경망의 역사
신경망의 역사는 1940년대까지 거슬러 올라갑니다. 처음에는 단순한 수학적 모델로 시작했으며, 1980년대 이후로 컴퓨팅 성능의 발전과 함께 급속도로 발전했습니다. 특히 2010년대에 들어와 딥러닝의 부상으로 신경망의 중요성이 더욱 강조되었습니다.
3. 신경망의 기본 구성 요소
신경망은 다음과 같은 기본 구성 요소로 이루어져 있습니다:
- 뉴런(Neuron): 입력을 받아서 활성화 함수에 따라 출력을 생성합니다.
- 레이어(Layer): 뉴런이 모여 하나의 층을 이룹니다. 일반적으로 입력층(Input Layer), 은닉층(Hidden Layer), 출력층(Output Layer)으로 구성됩니다.
- 가중치(Weights): 뉴런 간의 연결 강도를 나타내며, 학습을 통해 조정됩니다.
- 바이어스(Bias): 뉴런의 활성화 함수에 더해지는 값으로, 모델의 유연성을 높입니다.
4. 신경망의 동작 원리
신경망은 입력 데이터를 받아 각 뉴런의 가중치와 바이어스를 적용하여 출력을 계산합니다. 이 과정에서 활성화 함수를 사용하여 비선형성을 추가합니다. 출력은 다음 층으로 전달되며, 마지막 출력층에서는 최종 예측값을 생성합니다.
5. 신경망의 학습 과정
신경망의 학습 과정은 다음과 같습니다:
- 순전파(Forward Propagation): 입력 데이터를 통해 출력을 계산합니다.
- 손실 함수(Loss Function): 예측값과 실제값 간의 오차를 계산합니다.
- 역전파(Backpropagation): 오차를 최소화하기 위해 가중치와 바이어스를 조정합니다.
- 최적화 알고리즘(Optimization Algorithm): 경사 하강법 등을 사용하여 가중치와 바이어스를 업데이트합니다.
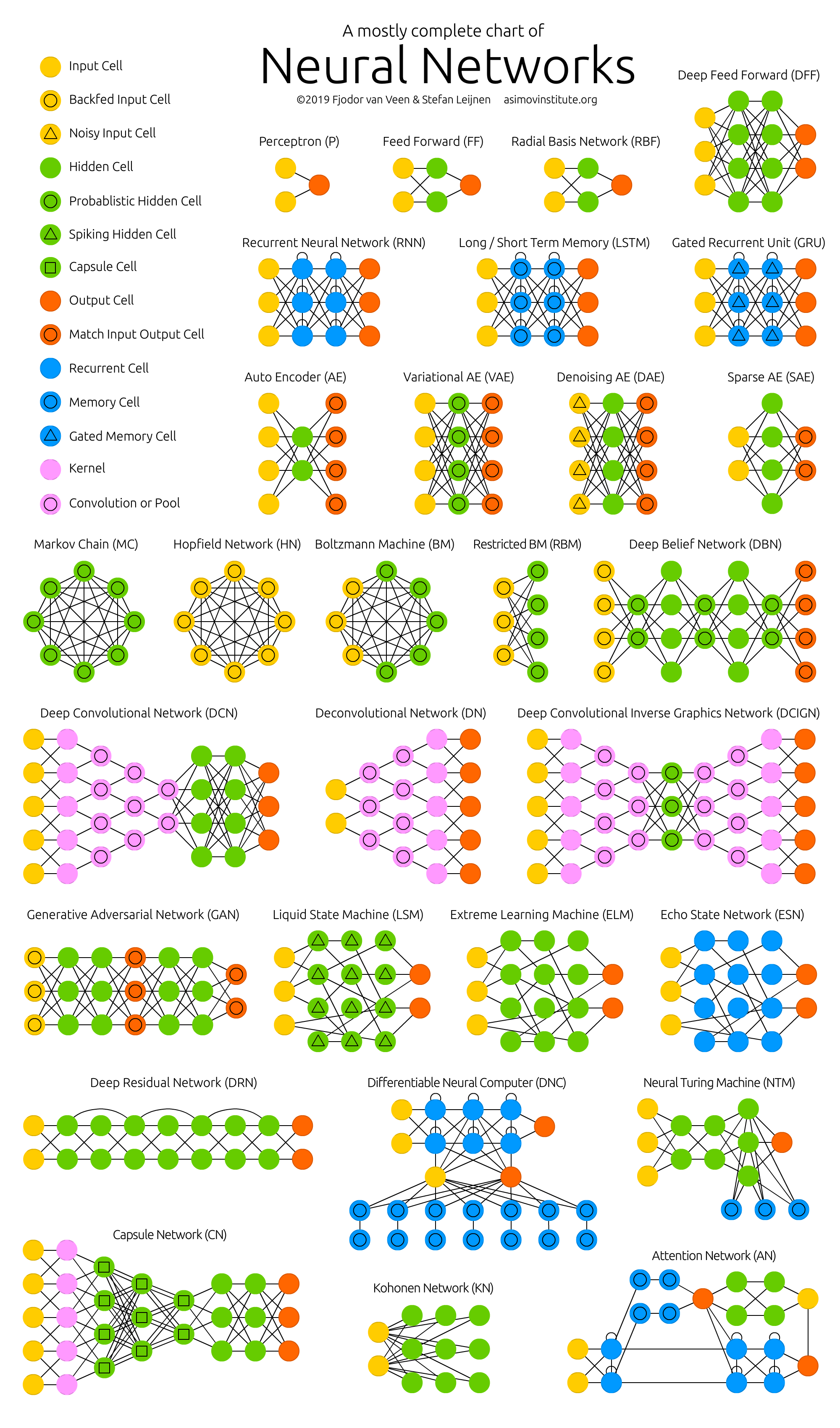
6. 다양한 신경망의 유형
신경망에는 여러 가지 유형이 있습니다. 주요 유형은 다음과 같습니다:
- 퍼셉트론(Perceptron): 단일층 신경망으로, 가장 기본적인 형태입니다.
- 다층 퍼셉트론(MLP, Multi-Layer Perceptron): 여러 개의 은닉층을 가진 신경망입니다.
- 합성곱 신경망(CNN, Convolutional Neural Network): 주로 이미지 처리에 사용됩니다.
- 순환 신경망(RNN, Recurrent Neural Network): 시계열 데이터나 자연어 처리에 사용됩니다.
7. 신경망의 주요 응용 분야
신경망은 다양한 분야에서 활용됩니다. 주요 응용 분야는 다음과 같습니다:
- 이미지 인식: 객체 탐지, 얼굴 인식 등
- 자연어 처리: 텍스트 분류, 번역, 음성 인식 등
- 추천 시스템: 사용자 취향 분석을 통한 추천
- 의료 진단: 질병 예측 및 진단 보조
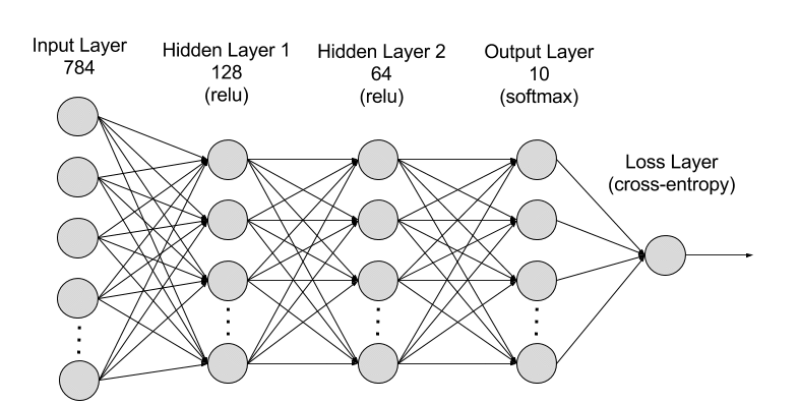
8. 신경망 구현 예제
다음은 PyTorch를 사용하여 간단한 신경망을 구현하는 예제입니다:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 데이터 전처리 및 로드
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
# 신경망 모델 정의
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 28 * 28)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
# 모델 초기화
model = SimpleNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 학습 함수 정의
def train(model, criterion, optimizer, train_loader, num_epochs=5):
for epoch in range(num_epochs):
for data, target in train_loader:
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
print(f'Epoch {epoch + 1}, Loss: {loss.item():.4f}')
# 학습 실행
train(model, criterion, optimizer, train_loader, num_epochs=5)9. 신경망의 장단점
장점:
- 복잡한 패턴 인식 및 데이터 분석이 가능
- 병렬 처리로 인한 빠른 연산 속도
- 다양한 분야에서 높은 성능을 보임
단점:
- 많은 데이터와 계산 자원이 필요
- 과적합(overfitting) 문제 발생 가능
- 모델 해석이 어려움
10. 결론
신경망은 현대 인공지능의 핵심 기술로, 다양한 문제를 해결하는 데 강력한 도구입니다. 기초 개념을 이해하고, 다양한 유형과 응용 분야를 학습함으로써 신경망을 효과적으로 활용할 수 있습니다. 신경망에 대한 지속적인 연구와 학습을 통해 더 많은 가능성을 탐구할 수 있을 것입니다.
관련 문서
https://aws.amazon.com/ko/what-is/neural-network/